ScreenMachine FLM images
In which I try to recover microscope images from 1993
When I visited recently, my Dad gave me a challenge: He handed me a box of 3.5" floppy disks1, which hold lots of images of minerals from an electron microscope. The challenge: Turn the images into something viewable with a modern computer.
I don’t have any computers with a floppy drive, though I do have a bunch of floppy drives not in computers ¯\_(ツ)_/¯. I did think my 11-year-old desktop had a floppy connector on the motherboard, but alas not. I had to borrow a USB floppy drive from a colleague to read the disks.
These images were taken on a scanning electron microscope at the Port Sunlight Laboratories of Unilever by the late Mike Rothwell (1938–1999).
Mike spent his early years in Somerset and obtained a B.Sc. in chemistry and Ph.D. at the University of Bristol. He went on to do post-graduate work in the USA at the Atomic Energy Commission in Ames, Iowa. He joined Unilever in 1966 and held several senior posts in Europe and the UK before retiring in November 1998.
Mike died suddenly on 20 May 1999 while engaged in his favourite hobby of collecting minerals on the Isle of Skye. He combined a high level of technical skill and expertise in mineralogy and geology with tremendous enthusiasm and an ability to instil the same enthusiasm in others. His generosity, integrity and perhaps most of all, his sense of humour are characteristics which those who knew him will always remember.
A prize fund was established at Bristol University by his widow, Nancy, with prizes being awarded annually for the best MSc student from a four-year course with a placement in industry; and for the best MSc student from a three-year course with a placement in a European university.

FLM Files
Each disk has a collection of .FLM files, so what on Earth are they?
The timestamps on the files are from December 1993 - January 1994, which
pre-dates all of the suggestions on the
file extension websites
by quite a bit.
Many file types start with a “magic number”, which helps indicate what they are, so we can take a peek in a hex editor to see if we have one of those:
$ head -c 64 AGATUSA.FLM | xxd -g 1 0000: 53 4d 31 2e 30 1a 90 05 01 00 98 02 f4 01 00 e4 SM1.0........... 0010: 03 08 08 08 02 c0 02 00 00 1e 90 23 01 00 00 00 ...........#.... 0020: 2d 00 00 00 3f 00 00 00 20 00 25 00 25 00 00 00 -...?... .%.%... 0030: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
Bingo! The first 5 bytes are the printable characters SM1.0.
A Google search for “SM1.0 FLM file” turns up an interesting document: Screen Machine II Movie Line VIDEO Developer Kit Reference Manual.
The file is from a website called The Best of NeXT Computers, and it describes the “Screen Machine” as a video capture and processing add-in card for NexT Computers, produced and sold around 1994. Sounds promising!
The reference manual gives a description of the FLM file format (page 4-142), defining the fields of a 64-byte header.
I started writing code to decode an FLM file header according to this format:
FLMID: SM1.0 TextEnd: 26 IconOffset: 66960 ImageWidth: 664 ImageHeight: 500 YUVMode: 0 YUVLength: 996 YBits: 8 UBits: 8 VBits: 8 CompressionMode: 2 OldCompression: 192 SourceMode: 2 IconLength: 7680 TextOffset: 74640 TextLength: 0 Contrast: 45 Brightness: 0 Saturation: 63 Hue: 0 Red: 32 Green: 37 Blue: 37 Reserved: [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
It looks pretty good, and the reference manual also tells us how the image data is stored - this is going to be easy!
Or not. Let me draw your attention to these lines from the reference manual (page 2-95):
SMImageHead.cCompMod Compression mode of the image data.
(Currently always 0)
SMImageHead.cOldComp Reserved
And these lines from my decoded header:
CompressionMode: 2 OldCompression: 192
Definitively not zero.
Awesome, so my FLM files are using some undocumented compression format for the image data.
We can confirm this by checking the entropy of the file.
Compressed data tends to have very high entropy, whilst uncompressed data tends
to have lower entropy. Using binwalk we can get a plot of the entropy of the
file, and it confirms that there’s a region of high entropy in the middle, right
where the image data should be:
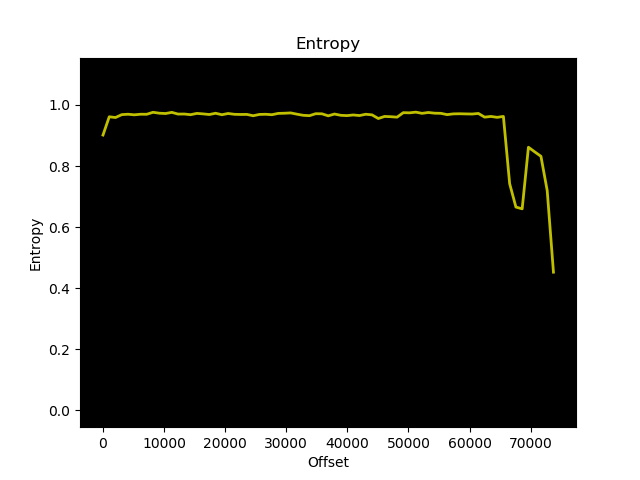
It also shows that the entropy drops at the end of the file - which corresponds to the “Icon” data - so from this it seems likely that the icon/thumbnail is not compressed.
Mystery Compression
OK, so what is CompressionMode: 2?
Luckily/sadly enough I’ve spent far too many hours messing around with computers, and so looking at the data in a hex editor, a couple of things stood out to me:
0000: 53 4d 31 2e 30 1a 90 05 01 00 98 02 f4 01 00 e4 SM1.0........... 0010: 03 08 08 08 02 c0 02 00 00 1e 90 23 01 00 00 00 ...........#.... 0020: 2d 00 00 00 3f 00 00 00 20 00 25 00 25 00 00 00 -...?... .%.%... 0030: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ 0040: ff d8 ff db 00 84 00 04 02 03 02 03 03 04 03 03 ................ 0050: 03 06 04 04 04 04 0a 06 06 05 05 06 0c 0e 0a 07 ................ 0060: 09 08 0c 0f 0f 0e 0c 0e 0d 10 12 0d 11 15 11 10 ................ 0070: 13 17 0e 14 1b 14 15 17 0f 19 1a 19 18 13 1c 1e ................ 0080: 1c 17 1e 19 19 19 18 01 04 04 04 06 05 06 0b 06 ................ 0090: 06 0b 18 10 0e 10 18 18 18 18 18 18 18 18 18 18 ................ 00a0: 18 18 18 18 18 18 18 18 18 18 18 18 18 18 18 18 ................ 00b0: 18 18 18 18 18 18 18 18 18 18 18 18 18 18 18 18 ................ 00c0: 18 18 18 18 18 18 18 18 ff c0 00 11 08 01 f4 02 ................ 00d0: 98 03 00 41 00 01 11 01 02 11 01 ff c4 01 a2 00 ...A............ 00e0: 00 01 05 01 01 01 01 01 01 00 00 00 00 00 00 00 ................ 00f0: 00 01 02 03 04 05 06 07 08 09 0a 0b 01 00 03 01 ................ 0100: 01 01 01 01 01 01 01 01 00 00 00 00 00 00 01 02 ................ 0110: 03 04 05 06 07 08 09 0a 0b 10 00 02 01 03 03 02 ................ 0120: 04 03 05 05 04 04 00 00 01 7d 01 02 03 00 04 11 .........}...... 0130: 05 12 21 31 41 06 13 51 61 07 22 71 14 32 81 91 ..!1A..Qa."q.2.. 0140: a1 08 23 42 b1 c1 15 52 d1 f0 24 33 62 72 82 09 ..#B...R..$3br.. 0150: 0a 16 17 18 19 1a 25 26 27 28 29 2a 34 35 36 37 ......%&'()*4567 0160: 38 39 3a 43 44 45 46 47 48 49 4a 53 54 55 56 57 89:CDEFGHIJSTUVW 0170: 58 59 5a 63 64 65 66 67 68 69 6a 73 74 75 76 77 XYZcdefghijstuvw 0180: 78 79 7a 83 84 85 86 87 88 89 8a 92 93 94 95 96 xyz............. 0190: 97 98 99 9a a2 a3 a4 a5 a6 a7 a8 a9 aa b2 b3 b4 ................ 01a0: b5 b6 b7 b8 b9 ba c2 c3 c4 c5 c6 c7 c8 c9 ca d2 ................ 01b0: d3 d4 d5 d6 d7 d8 d9 da e1 e2 e3 e4 e5 e6 e7 e8 ................ 01c0: e9 ea f1 f2 f3 f4 f5 f6 f7 f8 f9 fa 11 00 02 01 ................ 01d0: 02 04 04 03 04 07 05 04 04 00 01 02 77 00 01 02 ............w... 01e0: 03 11 04 05 21 31 06 12 41 51 07 61 71 13 22 32 ....!1..AQ.aq."2 01f0: 81 08 14 42 91 a1 b1 c1 09 23 33 52 f0 15 62 72 ...B.....#3R..br 0200: d1 0a 16 24 34 e1 25 f1 17 18 19 1a 26 27 28 29 ...$4.%.....&'() 0210: 2a 35 36 37 38 39 3a 43 44 45 46 47 48 49 4a 53 *56789:CDEFGHIJS 0220: 54 55 56 57 58 59 5a 63 64 65 66 67 68 69 6a 73 TUVWXYZcdefghijs 0230: 74 75 76 77 78 79 7a 82 83 84 85 86 87 88 89 8a tuvwxyz......... 0240: 92 93 94 95 96 97 98 99 9a a2 a3 a4 a5 a6 a7 a8 ................ 0250: a9 aa b2 b3 b4 b5 b6 b7 b8 b9 ba c2 c3 c4 c5 c6 ................ 0260: c7 c8 c9 ca d2 d3 d4 d5 d6 d7 d8 d9 da e2 e3 e4 ................ 0270: e5 e6 e7 e8 e9 ea f2 f3 f4 f5 f6 f7 f8 f9 fa ff ................ 0280: da 00 0c 03 00 00 01 11 02 11 00 3f 00 1f 8b 01 ...........?....
Those sections where the numbers are counting up and it looks like sections
of the alphabet - I’ve seen that kind of data frequently in JPEG files,
and the first two bytes of the image data: ff db, that’s a
JPEG Start-of-Image marker!2
So, it looks like the compressed image data is some kind of JPEG. Cool!
JPEG Decode
I dumped out the image data to a file and tried opening it as a JPEG. It does partially work, but decoding fails part-way through, and the image is corrupted beyond recognition. Here is one of the files, which your browser may or may not attempt to display:

The error thrown is “bad Huffman code”, which means that the decoder encountered a series of bits which it wasn’t able to map to one of the Huffman compression codes contained in the file.
I wrote a bunch more code, using the JPEG Standard (JPEG ISO/IEC 10918-1 ITU-T Recommendation T.81) as a reference to un-pick each of the component parts of the JPEG data.
Failure and Confusion
Long story short, I can’t at all figure out what’s wrong with the files.
All of the JPEG headers are fine - the DQT (Quantisation tables) and DHT (Huffman tables) are all the same for all of the files, and in-fact the Huffman values are identical to the reference values given in the ITU Specification Appendix K; so it doesn’t look like there’s anything wrong with the headers.
Every single one of the FLM files fails JPEG decoding - all 183 of them. If this was some kind of random data integrity problem with the disks (which would be understandable given their age), I would have expected at least some of the files to be OK.
Also, all of the header data is fine, and seems to match across all of the files. If there was random corruption so pervasive that it affects every single file, I would have expected at least some of the headers to be corrupted too.
I’ve tried several different decoders - libjpeg and derivatives, golang’s
standard library, and a couple of
minimal Python implementations.
All of them fail in the same way.
In one file, I’ve tried flipping bit values to see how it impacts decoding, and it doesn’t change very much. The “failure” seems quite stable - changing most bits doesn’t cause the failure point to move, and when it does change, it settles on other “stable” values. This again makes me think that this isn’t a problem caused by random bit corruption.
I also tried replacing whole bytes with every possible value, with much the same result as flipping individual bits.
To me this looks less like a corruption issue, and more like the JPEG encoder which produced the files was somehow incorrect or does something non-standard which can’t be decoded.
Icon Data
From the entropy plot, it looked like the icon data isn’t compressed, and the reference manual describes the format for the icon data, so I also extended my program to extract the icons.
There’s one minor difference in that the reference manual says all icons are 80x60 pixels, whereas mine are 80x64, but the data format matches and I was able to extract them.
The Chroma data is either corrupt or garbage3, but taking just the Luma I can get decent (albeit low resolution) grayscale images, giving a tantalising glimpse at what I’m missing out on by failing to decode the main image body.
![]()
Here’s a full mosaic of all of the thumbnails:

Can you help?
So, I’d really like to successfully decode the image bodies, but I’m at a bit of a loss for what to try next.
Perhaps someone out there has a NeXT computer and/or the Screen Machine software and could try importing the FLM files back into the software that (presumably) produced them.
Or, perhaps someone has some good ideas for how to debug the JPEG decode?
Looking at the blocks which do decode before the error, they still don’t look good - the coefficients are clearly all over the place, shown by the spotty appearance even in the very first block; so I don’t think the point at which the decode fails is really very indicative of where the problem is.
If you have any ideas, please do contact me - you can find my details for different platforms at the bottom of the page.
-
Remember those? We use them as coasters in our house) ↩︎
-
Most JPEG images are in the “JPEG File Interchange Format” , which has a
JFIFmagic number near the start of the file - that would have been a dead giveaway. However, this is not a JFIF file, but could still be a valid JPEG. ↩︎ -
I wonder if this is at-all related to the JPEG problem. Could it be that the chroma data actually wasn’t encoded, despite the JPEG headers saying it was? ↩︎